
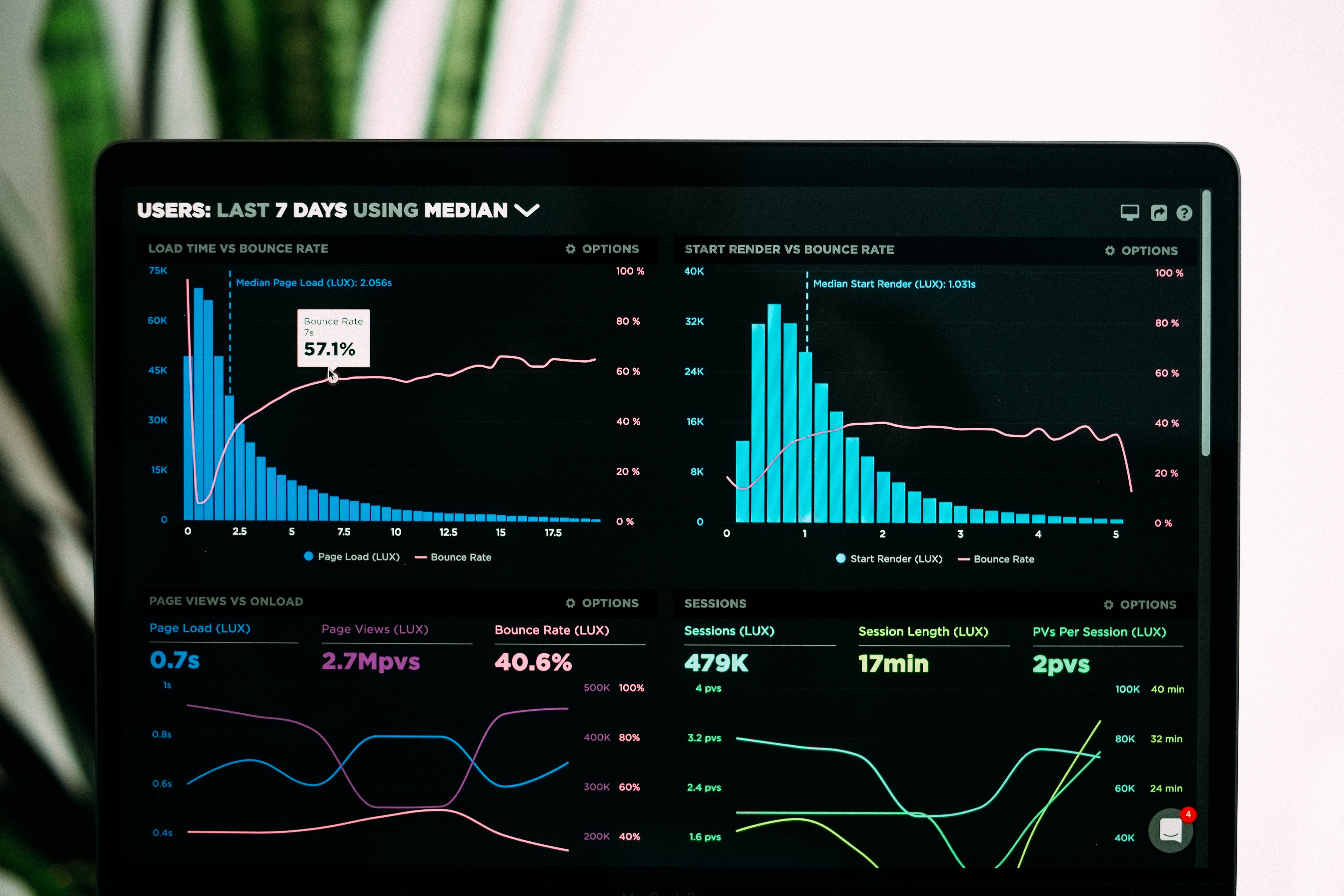
Rossmann Sales Prediction
Projeto de previsão de vendas de todas as unidades da Rossmann, para investimento de reforma para as próximas 6 semanas.
As ferramentas utilizadas foram:
- Python, Pandas, Numpy, Seaborn, Scikit-Learning, Scipy e Boruta.
- Anaconda e Jupyter Notebooks.
- Machine Learning com XGBoost Regressor.
- Render Cloud.
- Flask API
- Telegram Bot API

Construção de um Programa de Fidelidade com Clusterização de Clientes
Foi utilizado neste projeto: Python, Estatística e técnicas não-supervisionadas de
Machine Learning, para segmentar um grupo de clientes com base em suas características
de performance de compra, a fim de selecionar grupos de clientes para formar um programa
de Fidelidade com o objetivo de aumentar a receita da empresa. E o resultado dessa solução,
caso fosse implementada, seria de US$ 15MM de dólares de receita anual.
As ferramentas utilizadas foram:
- Git, Gitlab e Github.
- Jupyter Notebooks.
- K-means, Hierarquical Clustering, DBScan.
- AWS Cloud (EC2, S3, Postgree, SQLite)
- Metabase Visualization
Identificação de Imóveis para compra e revenda a fim de maximizar o lucro
Identificação de imóveis abaixo do preço médio de venda e definição do preço ideal de revenda, a partir de uma análise exploratória de dados em Python.
As ferramentas utilizadas foram:
- Python, Pandas, Numpy e Seaborn.
- Anaconda e Jupyter Notebooks.
- Mapas interativos com Plotly e Folium.
- Render Cloud.
- Streamlit Python framework web
Análise estatística de MaxDiff para Pesquisa de Mercado
Criação de projeto de análise estatística avançada
de MaxDiff, para a área de Consumer Insights, garantindo que o trabalho fosse feito internamente e trazendo uma
economia de $900,00 USD por projeto para a empresa Nielsen, no ramo de Pesquisa de Mercado.
As ferramentas utilizadas foram:
- R/RStudio.
- Microsoft Excel.

Projeto de roteirização de pontos de venda
Liderança na criação e condução do projeto de roteirização dos pontos de venda,
utilizando métodos de manipulação de dados, geolocalização, e visualização de dados
para a empresa Grupo Card.
As ferramentas utilizadas foram:
- Python, Pandas,e Geopandas.
- Geopy, GoogleV3 e Bing Maps.
- Mapas interativos com Folium.
